
{kind=link}
Other than SAPI5-compatible voices put in in your laptop, ActivePresenter 9 means that you can get extra third-party text-to-speech voices, together with Amazon Polly, Google Cloud, and Microsoft Azure. Hold studying as we speak’s tutorial to learn the way.
Textual content to Speech is a useful built-in characteristic in ActivePresenter that helps you create audio tracks proper inside the app. In ActivePresenter 9, it is possible for you to to entry exterior cloud voices from totally different voice suppliers to create your personal audio monitor. Sound fascinating? Obtain the newest model of ActivePresenter to find extra:


The article covers:
Allow Textual content to Speech characteristic
Get extra third-party Textual content-to-Speech voices
Let’s start!
Allow Textual content to Speech Characteristic
As talked about within the earlier article, the Textual content to Speech characteristic is a handy option to generate audio from textual content or convert closed captions to speech. You could find this characteristic within the Properties pane:
- Media tab of an audio object.
- Audio tab of an object with hooked up audio.
- Measurement & Properties tab of a CC node.
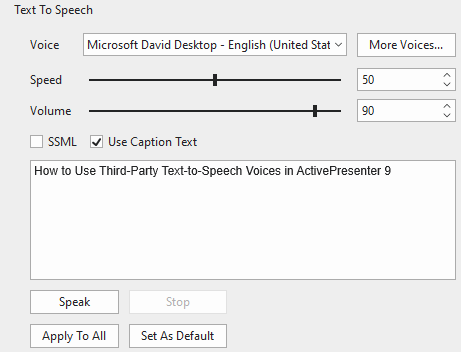
Right here, you’ll be able to select one voice from the Voice drop-down checklist, then modify the pace and quantity if you wish to. Getting accomplished by the way in which, it creates a TTS audio.
For extra element, see Use Textual content to Speech Characteristic.
If the obtainable voices within the Voice drop-down checklist don’t fulfill you, you’ll be able to click on Extra Voices… to entry different cloud voices. Nevertheless, you’ll want to do some additional settings. That will probably be mentioned within the subsequent half.
Get Extra Textual content-to-Speech Voices
Entry Voices
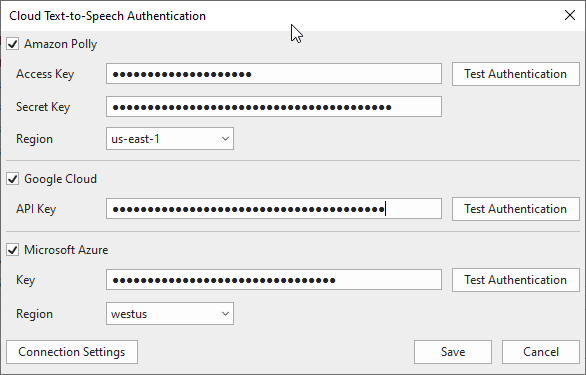
When you click on the Extra Voices… button, a Cloud Voices dialog seems permitting you to entry extra voices. Nevertheless, to make voices accessible, you first need to get authentication from the voice suppliers. Do the next:
Step 1: Both click on Authentication Settings (1) or Get Out there Voices (2).

After that, the Cloud Textual content-to-Speech Authentication dialog popping up means that you can enter authentication keys for any supplier whom you need to use their offered voices. Be aware that to get these entry keys, you’ll want to create an account in every corresponding supplier.
Beneath are some useful references that you could be need to check out:
Step 2: After coming into the keys, click on the Take a look at Authentication button to test in case your keys are legitimate.
Step 3: Click on Save to use and return to the Cloud Voices dialog.
Select Language
After you efficiently bought authentication, obtainable voices will seem within the Voice Choice part.
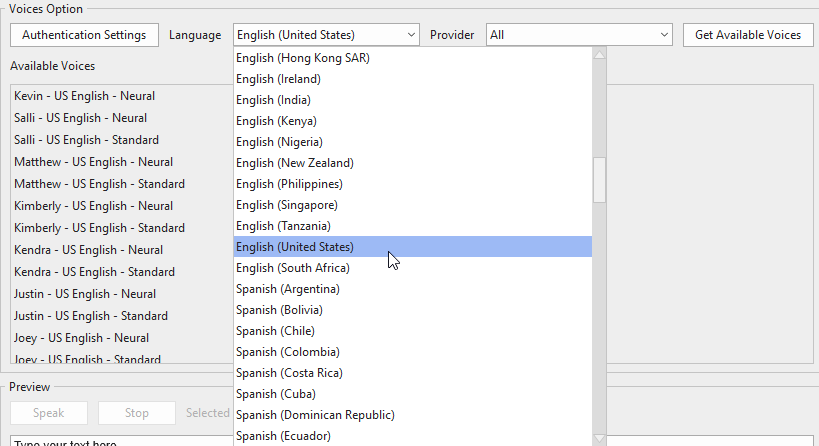
Right here, you’ll be able to:
- Click on the drop-down arrow within the Language combo field to decide on your required language.
- Click on the Supplier combo field to decide on amongst three suppliers, that are Amazon Polly, Google Cloud, Microsoft Azure, or all of them. The obtainable voices of the chosen language of the corresponding supplier will probably be proven within the Out there Voices checklist.
Preview Voices
To preview a voice, comply with these steps:
- Choose a voice within the Out there Voices checklist.
- Enter a textual content within the Preview textual content field.

3. Click on Communicate to hearken to the voice and click on Cease to cease listening.
Handle Voices
If you’re glad with a voice, you’ll be able to click on the Add button (3) so as to add that voice to the Added Voices checklist.
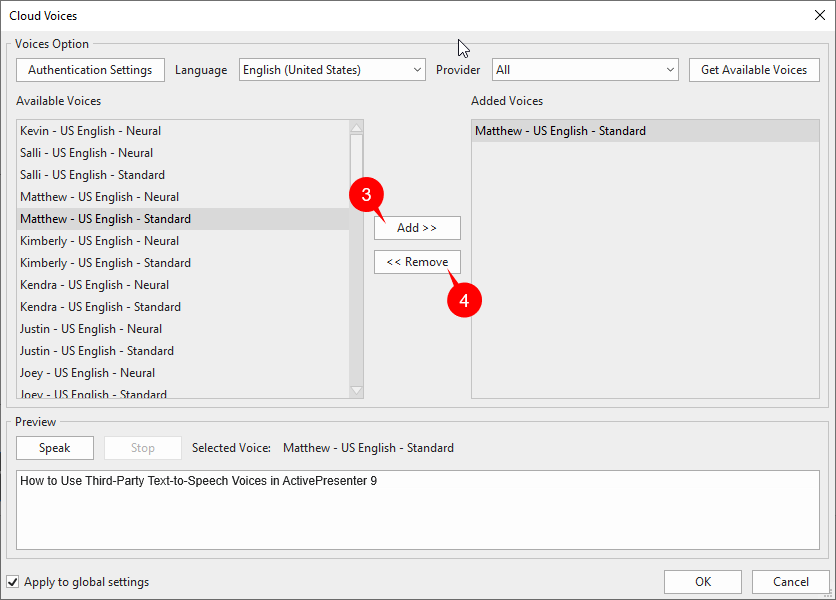
Then, the added voice will probably be proven within the Voice drop-down checklist of the Textual content to Speech part within the Properties pane, accordingly.
If you not want to make use of any voice, simply click on Take away (4). Consequently, that voice will not be displayed within the Voice checklist.
Use SSML Tags for SSML-Supported Voices
Many of the cloud voices are SSML (Speech Synthesis Markup Language) – supported voices. Which means you’ll be able to improve that voice with SSML tags. For instance, you need to use SSML tags so as to add pauses and different speech results resembling emphasis, quantity, talking charge, pitch, and extra to that voice.
Within the Textual content to Speech dialog, you’ll be able to:
- Select any cloud voices already added right here.
- Choose the SSML checkbox to allow this operate.
- Enter plain textual content with SSLM tags (eg. </communicate>, <break>, <prosody>, <phoneme>, <p>, <s>, and so on.)
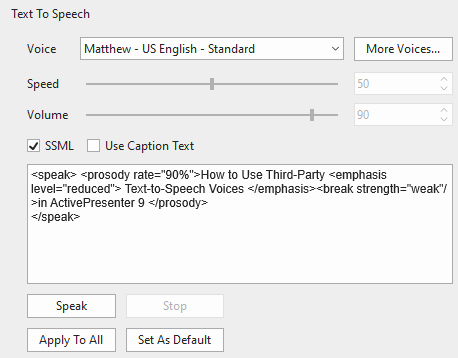
In the meantime, if you choose the Use Caption/Object Textual content checkbox, you simply merely modify the plain textual content with none SSML tags.
For extra details about supported SSML tags, you’ll be able to check out corresponding references: Amazon Polly, Google Cloud, and Microsoft Aruze.
That’s it. Now, you’ll be able to entry and modify extra third-party text-to-speech voices proper inside ActivePresenter 9. Be at liberty to contact us when you want any assist.
See extra: